Speed and power: fine-tuning distilled transformers models
![]()
Posted on Thu 25 February 2021
Over the past few years, transformers have spurted tremendous progress in natural language processing. This success is partly explained by their impressive scaling capabilities. It seems as if their perfomance improvement with the number of parameters had no ceiling, as emphasized in the GPT-3 paper by OpenAI. Following this observation, transformers models have become bigger and bigger. The latest Switch Transformer model from Google has more than a trillion parameters.
Using those humongous models for practical applications is challenging. Fine-tuning a transformer model for custom use-cases requires special hardware and setups, is costly, time-consuming, and inference may be slow.
Knowledge distillation to the rescue¶
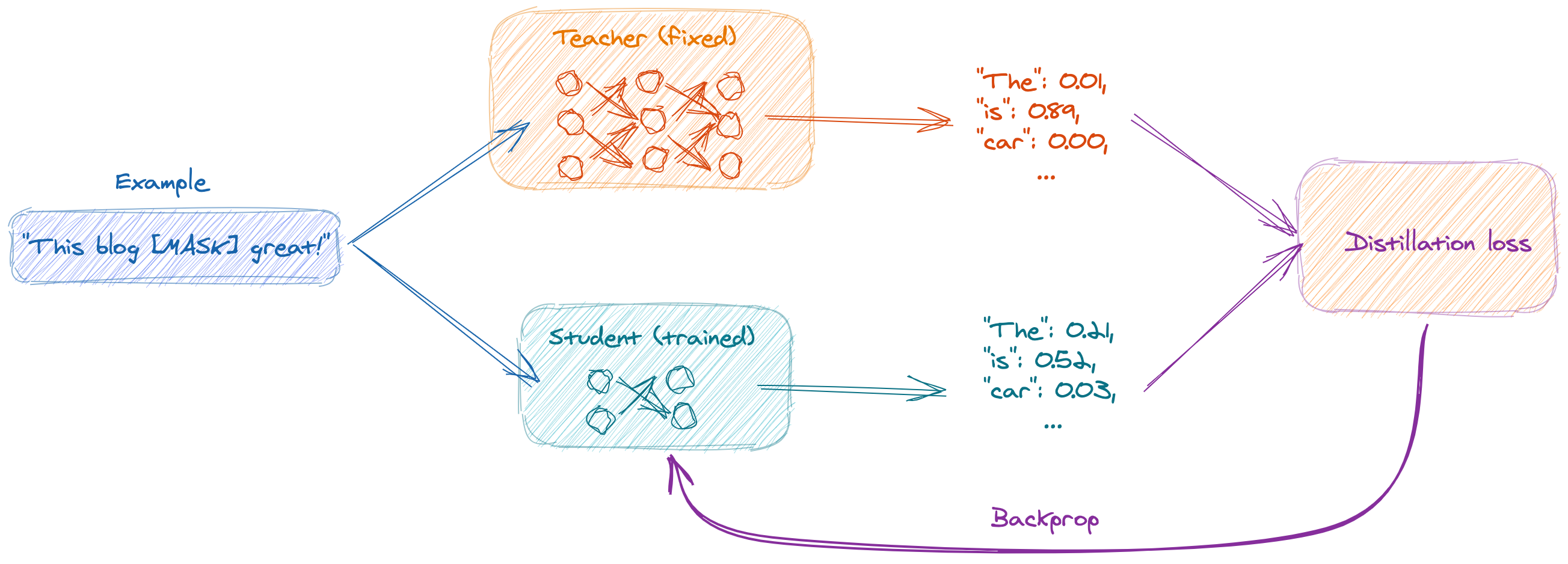
Luckily, part of the ML community focuses on producing leaner and faster transformers while retaining most of their predictive power. This is usually done via knowledge distillation, where a small model (the "student") is trained to reproduce the predictions of a larger model (the "teacher"). Knowledge distillation is different from the original classification task since for a given example the student's predictions ($s_i$) have to match probabilities predicted by the teacher ($t_i$), rather than binary labels. To train the student, one typically combines the regular log loss (that doesn't depend on the teacher) $L_\text{classif.} = \sum_i y_i \log (s_i)$ with a distillation loss (that takes into account the teacher) $L_\text{distil.} = \sum_i t_i \log (s_i).$
In practice, knowledge distillation benefits from a bunch of tricks such as probabilities smoothing, adding other terms to the loss functions, or pre-training the student modeel. More details here.
Using smaller transformers without missing out on performance¶
In my last post I've shown how to fine-tune DistilBERT for a multi-label classification task. DistilBERT is already a distilled version of BERT-base, with ~60M parameters instead of ~110M, but in this post my goal is to evaluate much smaller distilled versions of BERT, down to BERT-Tiny that was introduced in a Google paper with a slew of distilled BERT models. BERT-Tiny has only 2 transformer layers with 128 hidden units each (distributed among 2 self-attention heads), totalling a lean 4.4M parameters.
In addition to evaluating how fast and accurate this small transformer can be, I also introduce a few more items from the transformers toolbox. Notably, I use the PyTorch interface of the Transformers package. Like a lot of pre-trained transformers available in the Transformers package, the distilled versions of BERT mentionned above are only available as PyTorch models.
I run all of the experiments on the Toxic Comments multi-label classification dataset, for comparison with my previous post where I trained a "TD-IDF + logistic regression" baseline (validation loss = 0.281) and fine-tuned a DistillBERT model (validation loss = 0.043).
%%capture
!pip uninstall -y kaggle && pip install kaggle
# Needed to get the latest version of the Kaggle CLI
from getpass import getpass
import os
# We'll use the Kaggle-CLI to download the dataset
# To create an authentication token on Kaggle check https://www.kaggle.com/docs/api
# You'll also have to accept the competition rules here:
# https://www.kaggle.com/c/jigsaw-toxic-comment-classification-challenge/rules
os.environ["KAGGLE_USERNAME"] = getpass(prompt='Kaggle username: ')
os.environ["KAGGLE_KEY"] = getpass(prompt='Token: ')
!kaggle --version
!kaggle competitions download -c jigsaw-toxic-comment-classification-challenge
!unzip jigsaw-toxic-comment-classification-challenge.zip && unzip train.csv.zip
import pandas as pd
from sklearn.model_selection import train_test_split
dataset = pd.read_csv("train.csv")
texts = list(dataset["comment_text"])
label_names = dataset.drop(["id", "comment_text"], axis=1).columns
labels = dataset[label_names].values
train_texts, test_texts, train_labels, test_labels = train_test_split(
texts, labels, test_size=0.2, random_state=42
)
sample_idx = 23
print(f'Sample: "{train_texts[sample_idx]}"')
print(f"Labels: {pd.Series(train_labels[sample_idx], label_names).to_dict()}")
Fine-tuning BERT-Tiny¶
The BERT-Tiny model is available with 24 distilled models under the Google transformers repository, accessible through the Transformers package
!pip install -q transformers > /dev/null
import transformers
print(f"Transformers package version: {transformers.__version__}")
from transformers import AutoConfig, AutoTokenizer, AutoModel
MAX_LENGTH = 200
BATCH_SIZE = 16
LEARNING_RATE = 1e-05
MODEL_NAME = "google/bert_uncased_L-2_H-128_A-2"
config = AutoConfig.from_pretrained(MODEL_NAME)
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
transformer_model = AutoModel.from_pretrained(MODEL_NAME)
We've now loaded th pre-trained models. Let's create a PyTorch Dataset as an interface between the data used for fine-tuning the model, and the model.
The Dataset interface is convenient because it allows you to handle datasets that fit entirely in the memory (as is the case for us now), but also datasets that are larger and have to be pre-loaded by chunks from the disk during training.
import numpy as np
import pandas as pd
from sklearn import metrics
import transformers
import torch
from torch.utils.data import Dataset, DataLoader
device = 'cuda' if torch.cuda.is_available() else 'cpu'
class TransformersDataset(Dataset):
"""Encode texts and return them with their corresponding labels."""
def __init__(self, texts, labels, tokenizer, max_length):
"""Tokenize the corpus of texts and store them with the labels,
as PyTorch tensors."""
self.encoded_inputs = tokenizer(texts, truncation=True, padding=True,
max_length=max_length, return_tensors="pt")
self.labels = torch.tensor(labels, dtype=torch.float)
def __len__(self) -> int:
"""In PyTorch datasets have to override the length method."""
return len(self.labels)
def __getitem__(self, index: int) -> dict:
"""This method defines how to feed the data during model training."""
inputs_ands_labels = dict()
for key in ["input_ids", "attention_mask", "token_type_ids"]:
inputs_ands_labels[key] = self.encoded_inputs[key][index]
inputs_ands_labels['labels'] = self.labels[index]
return inputs_ands_labels
train_dataset = TransformersDataset(train_texts, train_labels, tokenizer, MAX_LENGTH)
test_dataset = TransformersDataset(test_texts, test_labels, tokenizer, MAX_LENGTH)
training_loader = DataLoader(train_dataset, BATCH_SIZE, shuffle=True, num_workers=0)
testing_loader = DataLoader(test_dataset, BATCH_SIZE, shuffle=False, num_workers=0)
We can now define the PyTorch model. Note that we have to define a custom model because we are dealing with a custom use-case (multi-label classification). For multi-class classification you can directly fine-tune the transformer model without extracting it into a PyTorch module.
The signature of our custom transformer is chosen to be compatible with the Transformers Trainer, a very convenient class that does all of the training and logging for us. If you want to see the full PyTorch version that doesn't use the Trainer, but relies on PyTorch Lightning instead, check the bonus section at the end of this post.
from torch.nn.functional import binary_cross_entropy_with_logits
class MultiLabelTransformer(torch.nn.Module):
"""PyTorch module used to fine-tune a transformer model.
The structure of this class is meant to be compatible with the Trainer from the
Transformers library: https://huggingface.co/transformers/main_classes/trainer.html
"""
def __init__(self, transformer_model, config, n_labels):
super().__init__()
self.transformer_model = transformer_model
self.dropout = torch.nn.Dropout(config.hidden_dropout_prob)
self.classifier = torch.nn.Linear(config.hidden_size, n_labels)
def forward(self, input_ids, attention_mask=None, token_type_ids=None, labels=None):
"""During fine-tuning, attention masks, token types ids have to be passed as
argument, with the labels. During inference, the model simply accepts a sequence
of tokens ids and produces a set of binary logit scores.
"""
pooled_output = self.transformer_model(
input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids
).pooler_output
pooled_output = self.dropout(pooled_output)
logits = self.classifier(pooled_output)
if labels is None:
return logits
else:
return binary_cross_entropy_with_logits(logits, labels), logits
model = MultiLabelTransformer(transformer_model, config, train_labels.shape[1])
model.to(device) # Move our model from memory to the GPU's memory
optimizer = torch.optim.Adam(params=model.parameters(), lr=LEARNING_RATE)
from transformers import Trainer, TrainingArguments
training_args = TrainingArguments(
output_dir='./results',
num_train_epochs=3,
per_device_train_batch_size=BATCH_SIZE,
per_device_eval_batch_size=BATCH_SIZE,
warmup_steps=500,
weight_decay=0.01,
logging_dir='./logs',
evaluation_strategy="epoch",
logging_first_step=True,
logging_steps=10000
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=test_dataset
)
trainer.train()
# Uncomment the lines below if you want to visualize metrics with TensorBoard
# %load_ext tensorboard
# %tensorboard --logdir logs
How fast! Remember that fine-tuning DistilBERT for 3 epochs took close to an hour with the same dataseet and hardware. Here, we obtain similar performances (validation loss around 0.043) in only 7 minutes! Let's check the inference latency.
torch.save(model, "./model.pt")
Inference¶
import pandas as pd
from time import time
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
loaded_model = torch.load("./model.pt")
loaded_model.eval() # Run to finish loading the model
def score_text(text, tokenizer=tokenizer, model=loaded_model):
"""Tokenize and score a single text."""
inputs = tokenizer.encode_plus(
text, max_length=MAX_LENGTH, padding='max_length',
return_token_type_ids=False, return_attention_mask=False
)
token_ids = torch.tensor(inputs['input_ids'], dtype=torch.long).reshape(1, -1)
token_ids = token_ids.to(device)
logits = model(token_ids)
scores = torch.sigmoid(logits[0])
return scores.cpu().detach().numpy()
text = """I am a nice Wikipedia user, I mean no harm,
I will not insult anybody or be offensive anyhow."""
t0 = time()
scores = score_text(text)
latency = time()-t0
scores = pd.Series(scores, label_names, name="scores")
print(scores.to_frame())
print(f"\nLatency: {latency:.3f} seconds")
Blazingly fast ⚡️. You can ship your model as an API (using Cortex, for instance), and nobody should complain about its latency.
To sum up, we trained an extremely distilled version of BERT (4.4M parameters instead of 110M) on ~150k comments from Wikipedia in only 7 minutes. We obtain similar performance (validation loss of 0.04) as with DistilBERT for the same number of epochs, i.e. doing way better than a random predictor (validation loss of 0.30) and than a standard ML baseline (validation loss of 0.28). Inference only takes on the order of 5 milliseconds.
Those smaller, distilled BERT models are promising for practical applications when needing faster training or inference time, or when using modest hardware.
Give them a try next time you want to train a Transformer model! 🤙
Bonus: fine-tuning with PyTorch Lightning¶
I also experimented with training the model only with PyTorch, while just using the Transformers library to download and extract the pre-trained BERT-Tiny model.
I found that, similarly to Keras for TensorFlow, PyTorch Lightning makes your life easier when using PyTorch The developers even provide a nice template to customize to your needs.
%%capture
!pip install pytorch-lightning pytorch-lightning-bolts
import pytorch_lightning as pl
from pytorch_lightning.metrics import Accuracy, AveragePrecision
from torch.nn.functional import binary_cross_entropy_with_logits
class LightningTransformer(pl.LightningModule):
def __init__(self, transformer_model, config, n_labels):
super().__init__()
self.transformer_model = transformer_model
self.dropout = torch.nn.Dropout(config.hidden_dropout_prob)
self.n_labels = n_labels
self.classifier = torch.nn.Linear(config.hidden_size, n_labels)
def forward(self, batch):
input_ids = batch['input_ids']
attention_mask = batch['attention_mask']
token_type_ids = batch['token_type_ids']
pooled_output = self.transformer_model(
input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids
).pooler_output
pooled_output = self.dropout(pooled_output)
logits = self.classifier(pooled_output)
return logits
def training_step(self, batch, batch_idx):
labels = batch["labels"]
outputs = self.forward(batch)
loss = binary_cross_entropy_with_logits(outputs, labels)
self.log('train_loss', loss)
return loss
def validation_step(self, batch, batch_idx):
labels = batch["labels"]
outputs = self.forward(batch)
loss = binary_cross_entropy_with_logits(outputs, labels)
self.log('val_loss', loss)
scores = torch.sigmoid(outputs)
preds = scores.round()
matches = torch.tensor(preds == labels, dtype=torch.float)
self.log('binary_accuracy', matches.mean())
self.log('multilabel_accuracy', matches.min(axis=1).values.mean())
return loss
def test_step(self, batch, batch_idx):
return self.validation_step(batch, batch_idx)
def configure_optimizers(self):
optimizer = torch.optim.Adam(self.parameters(), lr=LEARNING_RATE)
return optimizer
n_labels = train_labels.shape[1]
lightning_transformer = LightningTransformer(transformer_model, config, n_labels)
trainer = pl.Trainer(gpus=1, max_epochs=3, progress_bar_refresh_rate=20)
trainer.fit(lightning_transformer, training_loader, testing_loader)